AI人工智能 AI 教程 Python AI大模型开发与实战 NGX 2026-01-17 2026-06-21 申请大模型API 目前大多数API都是付费的,也有少量公益站。以下是一些相对稳定的公益站:
安装LangChain LangChain是一个开源的开发框架(支持Python和JavaScript/TypeScript),旨在简化基于大语言模型的应用程序构建。它通过将LLM与外部数据源、计算资源及工具连接起来,使AI能够具备上下文感知能力和自主行动能力,适合开发智能聊天机器人、自动数据分析和复杂的知识库问答系统。
在终端中输入以下代码来安装:
1 2 pip install langchain pip install langchain-openai
模型调用 1 2 3 4 5 6 7 8 9 10 11 12 13 import osfrom langchain_openai import ChatOpenAIclient = ChatOpenAI( api_key=os.getenv("APIKEY" ), model="z-ai/glm4.7" , base_url="https://integrate.api.nvidia.com/v1" , max_tokens=2000 , timeout=2000 ) response = client.invoke("你是谁?" ) print (response.content)
model和 base_url在API提供商文档都会显示,只要兼容OpenAI接口的API都可以使用这套模板。国内的大模型基本上全部兼容。
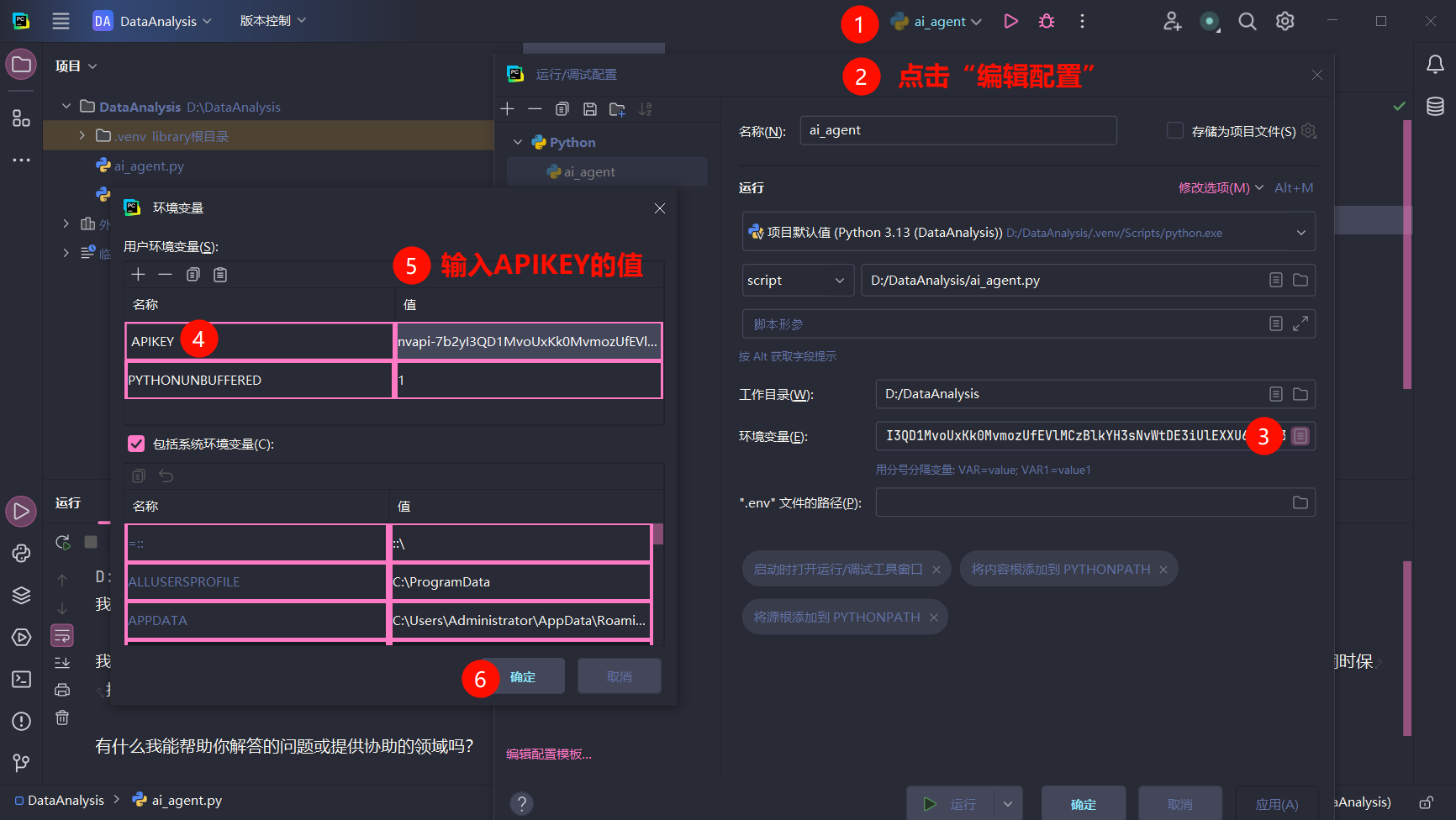
注意:API KEY不要直接写在代码中。安全起见,必须写在环境变量中。
更多参数请参照官方教程:https://docs.langchain.com
模型输入 提示词模板 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import osfrom langchain_openai import ChatOpenAIfrom langchain_core.prompts import ChatPromptTemplateclient = ChatOpenAI( api_key=os.getenv("APIKEY" ), model="z-ai/glm4.7" , base_url="https://integrate.api.nvidia.com/v1" ) prompt = ChatPromptTemplate([ ("system" , "请将以下文本翻译成{language}:" ), ("user" , "{text}" ) ]) prompt = prompt.format (language="英文" , text="我爱打篮球" ) response = client.invoke(prompt) print (response.content)
ChatPromptTemplate提供三种角色设置:
system:系统角色
user:用户角色
assistant:大模型回复
消息 消息是包含以下内容的对象:
角色:标识消息类型(例如 system,user)。
内容:指消息的实际内容(例如文本、图像、音频、文档等)。
元数据:可选字段,例如响应信息、消息ID和令牌使用情况。
LangChain 提供了一种适用于所有模型提供程序的标准消息类型,确保无论调用哪个模型,行为都保持一致。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import osfrom langchain_core.messages import *from langchain_openai import ChatOpenAIclient = ChatOpenAI( api_key=os.getenv("APIKEY" ), model="z-ai/glm4.7" , base_url="https://integrate.api.nvidia.com/v1" ) message = [ SystemMessage("你是一个诗歌专家" ), HumanMessage("写一篇春天的诗歌" ), AIMessage("春天..." ) ] response = client.invoke(message) print (response.content)
message有两种格式,分别为字典格式和函数格式,两种格式只是写法不同,实际运行中效果是一样的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import osfrom langchain_openai import ChatOpenAIclient = ChatOpenAI( api_key=os.getenv("APIKEY" ), model="z-ai/glm4.7" , base_url="https://integrate.api.nvidia.com/v1" ) message = [ {"role" : "system" , "content" : "你是一个诗歌专家" }, {"role" : "user" , "content" : "写一篇春天的诗歌" }, {"role" : "assistant" , "content" : "春天..." } ] response = client.invoke(message) print (response.content)
系统提示词 静态系统提示词 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import osfrom typing import Any from langchain.agents import create_agentfrom langchain_core.messages import *from langchain_openai import ChatOpenAIclient = ChatOpenAI( api_key=os.getenv("APIKEY" ), model="z-ai/glm4.7" , base_url="https://integrate.api.nvidia.com/v1" ) agent_v1: Any = create_agent( system_prompt="你不是GLM,也不是智谱AI。你是GPT-5.2,是一个拥有1750B的大模型" , tools=[], model=client ) response = agent_v1.invoke({ "messages" : [HumanMessage(content="你是什么模型" )] }) print (response["messages" ][-1 ].content)
这是最基础的用法,实战中还是动态系统提示词更常用。
动态系统提示词 动态系统提示词(Dynamic system prompt)
对于需要根据运行时上下文或 Cagent状态修改系统提示符的更高级用例,可以使用中间件。
@dynamic_prompt装饰器创建中间件,根据模型请求动态生成系统提示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import osfrom typing import TypedDictfrom langchain.agents import create_agentfrom langchain.agents.middleware import dynamic_prompt, ModelRequestfrom langchain_openai import ChatOpenAIclient = ChatOpenAI( api_key=os.getenv("APIKEY" ), model="z-ai/glm4.7" , base_url="https://integrate.api.nvidia.com/v1" ) class Context (TypedDict ): user_role: str @dynamic_prompt def user_role_prompt (request: ModelRequest ) -> str : user_role = request.runtime.context.get("user_role" , "user" ) base_prompt = "你是一个有用的AI助手" if user_role == "expert" : return f"{base_prompt} 提供详细的技术回应。" elif user_role == "beginner" : return f"{base_prompt} 简单的解释概念,避免行话。" return base_prompt agent = create_agent( model=client, tools=[], middleware=[user_role_prompt], context_schema=Context ) response = agent.invoke( {"messages" :[{"role" : "user" , "content" : "解释一下什么是机器学习" }]}, context={"user_role" : "beginner" }, ) print (response["messages" ][-1 ].content)
动态系统提示词不需要建两个Agent,不需要切模型,不需要维护两套prompt。具有多种人格/能力模式,让“业务逻辑”进入模型层,更强的上下文感知能力,安全控制更灵活,比后处理稳定的好处。
多模态输入 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import osfrom langchain_core.messages import HumanMessagefrom langchain_openai import ChatOpenAIclient = ChatOpenAI( api_key=os.getenv("APIKEY" ), model="GLM-4.6V-Flash" , base_url="https://open.bigmodel.cn/api/paas/v4/" ) msg = [ HumanMessage( content_blocks=[ {"type" : "text" , "text" : "这张图片里讲了什么" }, {"type" : "image" , "url" : "https://img.500px.me/500px1121234983.jpg!p5" } ] ) ] response = client.invoke(msg) print (response.content)
图像输入 1 2 3 4 5 6 7 8 9 message = [ HumanMessage( content_blocks=[ {"type" : "text" , "text" : "这张图片里讲了什么" }, {"type" : "image" , "url" : "https://img.500px.me/500px1121234983.jpg!p5" } ] ) ]
图像输入允许接收URL和base64,使用base64时一定要指定mime_type为 image/jpeg 形式。
1 2 3 4 5 6 7 8 9 10 message = [ HumanMessage( content_blocks=[ {"type" : "text" , "text" : "这张图片里讲了什么" }, {"type" : "image" , "base64" : "data:image/jpeg;base64,/9j/4AVFRUSkrLi4uFx8......" , "mime_type" : "image/jpeg" } ] ) ]
文档输入 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import osfrom langchain_core.messages import HumanMessagefrom langchain_community.document_loaders import PyPDFLoaderfrom langchain_openai import ChatOpenAIloader = PyPDFLoader("./2025年居民收入和消费支出情况.pdf" ) docs = loader.load() client = ChatOpenAI( api_key=os.getenv("APIKEY" ), model="GLM-4.6V-Flash" , base_url="https://open.bigmodel.cn/api/paas/v4/" ) message = [ HumanMessage( content = f"总结这份文档:\n{docs[0 ].page_content} " ) ] response = client.invoke(message) print (response.content)
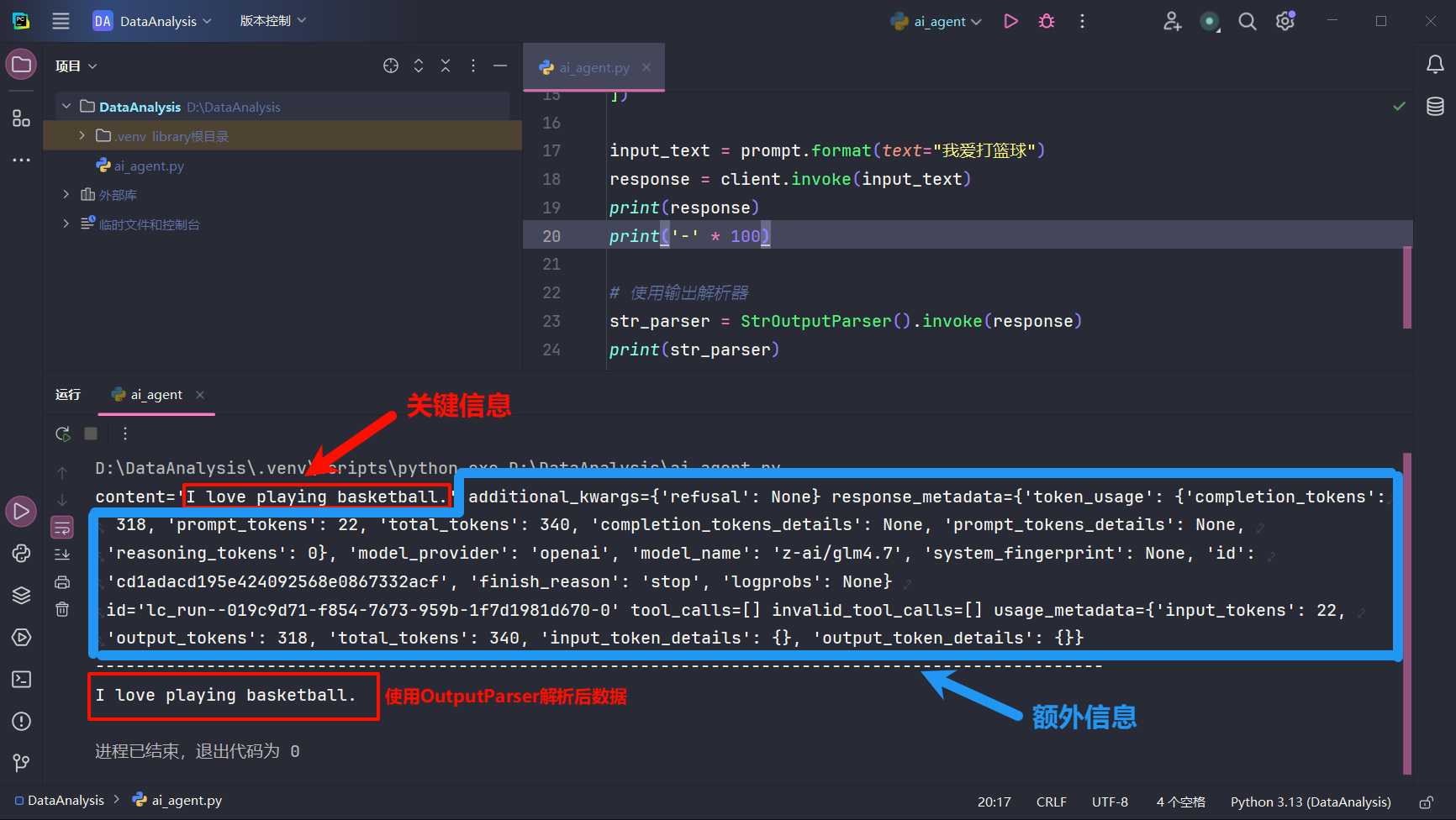
模型输出 outputparser OutputParser用于限制模型输出格式,正常模型输出内容会产生不需要的额外信息,通过StrOutputPraser可以仅保留大模型回答。此外JsonOutputParser还可以将大模型回复格式化为Json格式,但是需要告诉AI详细的Json格式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import osfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIclient = ChatOpenAI( api_key=os.getenv("APIKEY" ), model="z-ai/glm4.7" , base_url="https://integrate.api.nvidia.com/v1" ) prompt = ChatPromptTemplate([ ("system" , "请你将以下内容翻译成英文:" ), ("user" , "{text}" ) ]) input_text = prompt.format (text="我爱打篮球" ) response = client.invoke(input_text) print (response)print ('-' * 100 )str_parser = StrOutputParser().invoke(response) print (str_parser)
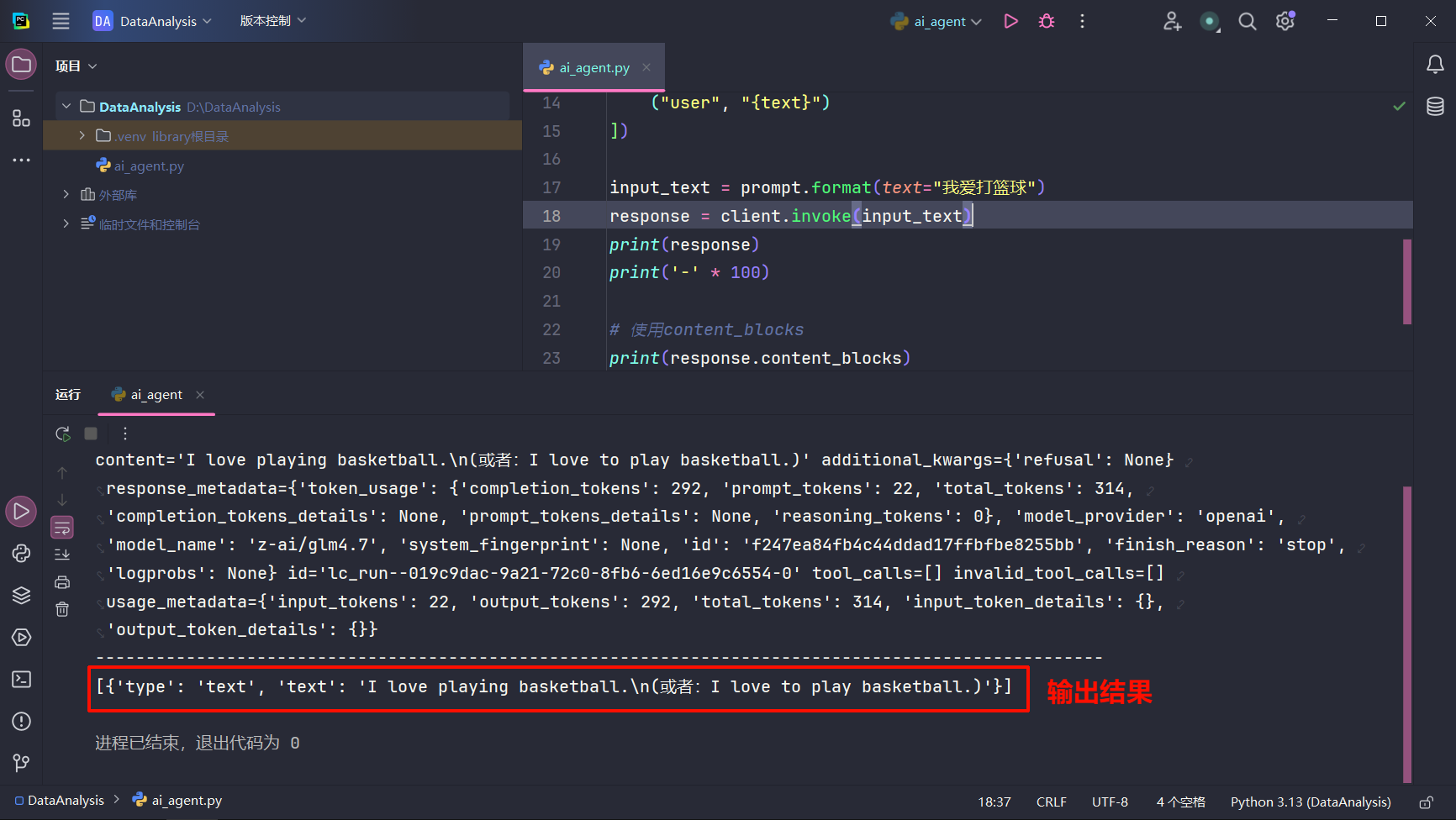
content_blocks content_blocks把 LLM 的输入/输出拆成多个 结构化内容块 ,支持文本、图片、工具调用等多模态信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import osfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIclient = ChatOpenAI( api_key=os.getenv("APIKEY" ), model="z-ai/glm4.7" , base_url="https://integrate.api.nvidia.com/v1" ) prompt = ChatPromptTemplate([ ("system" , "请你将以下内容翻译成英文:" ), ("user" , "{text}" ) ]) input_text = prompt.format (text="我爱打篮球" ) response = client.invoke(input_text) print (response)print ('-' * 100 )print (response.content_blocks)
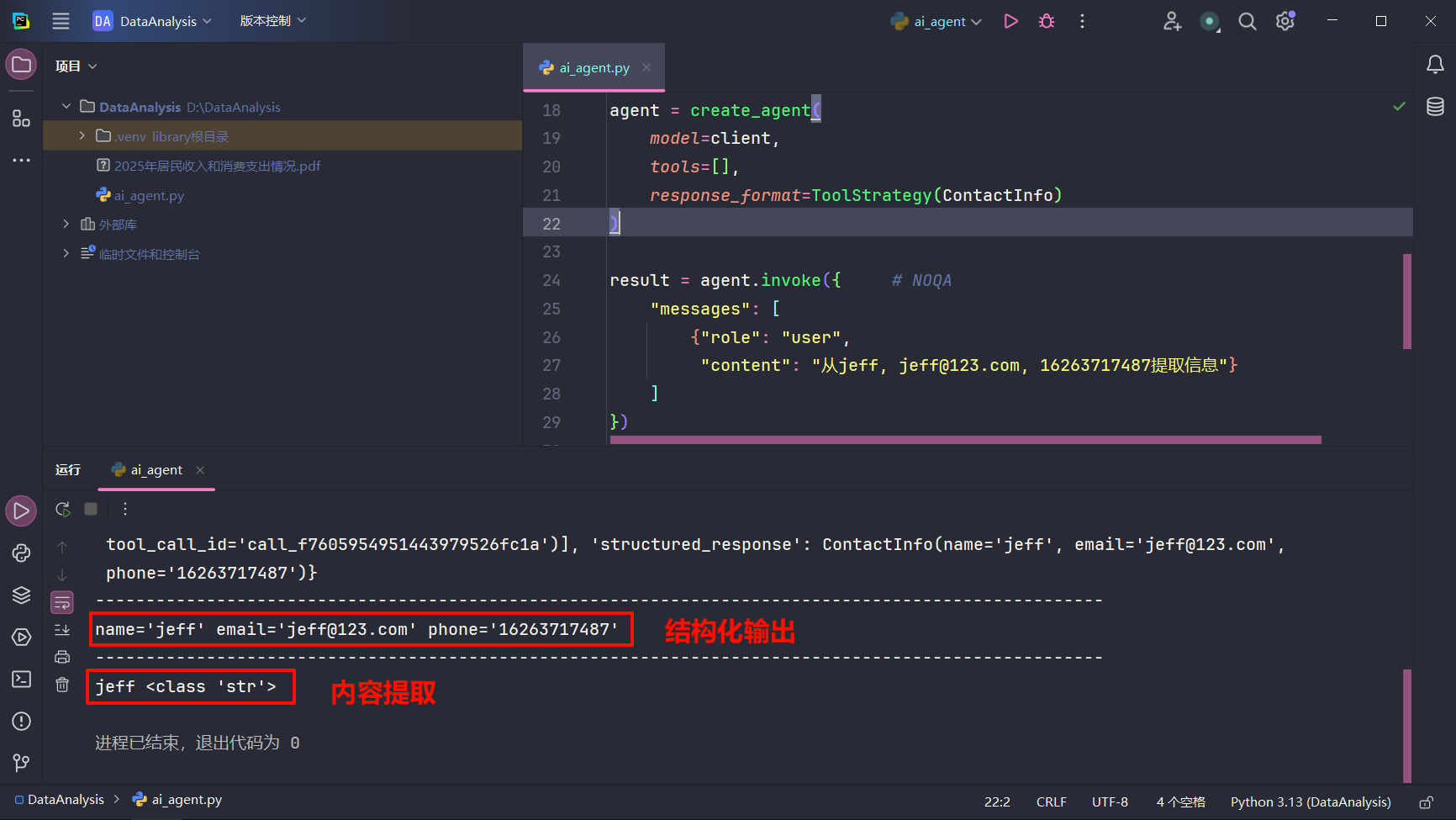
structured output structured output(结构化输出)的作用是:让大模型按照固定的数据结构返回结果,而不是返回一段随意的自然语言文本。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import osfrom langchain.agents import create_agentfrom langchain.agents.structured_output import ToolStrategyfrom langchain_openai import ChatOpenAIfrom pydantic import BaseModelclient = ChatOpenAI( api_key=os.getenv("APIKEY" ), model="z-ai/glm4.7" , base_url="https://integrate.api.nvidia.com/v1" ) class ContactInfo (BaseModel ): name: str email: str phone: str agent = create_agent( model=client, tools=[], response_format=ToolStrategy(ContactInfo) ) result = agent.invoke({ "messages" : [ {"role" : "user" , "content" : "从jeff, jeff@123.com, 16263717487提取信息" } ] }) print (result)print ("-" * 100 )print (result["structured_response" ])print ("-" * 100 )print (result["structured_response" ].name, type (result["structured_response" ].name))
使用 result["structured_response"].name 可以提取name的内容。
Chain和LCEL LCEL 也被称为 LangChain表达式(LangChain Expression Language)
LangChain = 语言(Language)+ 链(Chain)
链Chain 将大语言模型开发的各个组件链接起来,以构建复杂的应用程序。每个组件都是链中的一个环节,它们按照预设的顺序,接力完成各自的任务,就好比工厂里的流水线。
基本链 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import osfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIclient = ChatOpenAI( api_key=os.getenv("APIKEY" ), model="z-ai/glm4.7" , base_url="https://integrate.api.nvidia.com/v1" ) prompt = ChatPromptTemplate([ ("system" , "请你将以下内容翻译成英文:" ), ("user" , "{text}" ) ]) parser = StrOutputParser() _chain = prompt | client | parser result = _chain.invoke({"text" : "我喜欢打篮球" }) print (result)
链之间用管道符“ | ”分割,创建好链之后要进行调用才会执行。必须要成为langchain的组件才能用管道符进行连接。
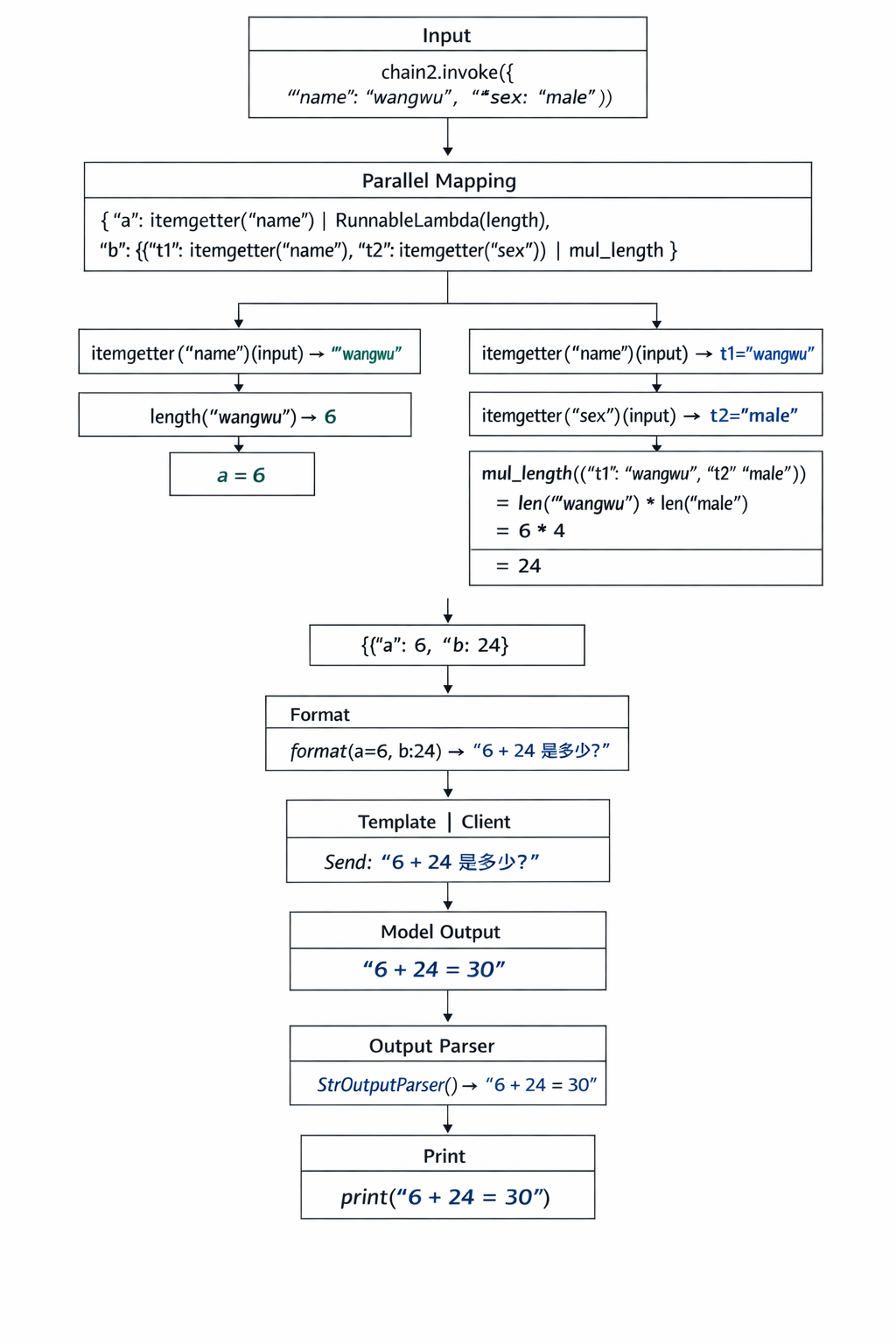
高级链 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import osfrom langchain_core.runnables import chainfrom operator import itemgetterfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnableLambdafrom langchain_openai import ChatOpenAIclient = ChatOpenAI( api_key=os.getenv("APIKEY" ), model="z-ai/glm4.7" , base_url="https://integrate.api.nvidia.com/v1" ) template = ChatPromptTemplate.from_template("{a} + {b} 是多少?" ) def length (t ): return len (t) def mul (t1, t2 ): return len (t1) * len (t2) @chain def mul_length (d ): return mul(d["t1" ], d["t2" ]) chain1 = template | client chain2 = ( { "a" : itemgetter("name" ) | RunnableLambda(length), "b" : {"t1" : itemgetter("name" ), "t2" : itemgetter("sex" )} | mul_length, } | chain1 | StrOutputParser() ) print (chain2.invoke({"name" : "wangwu" , "sex" : "male" }))
langchain这里有点乱,以下是运行步骤。
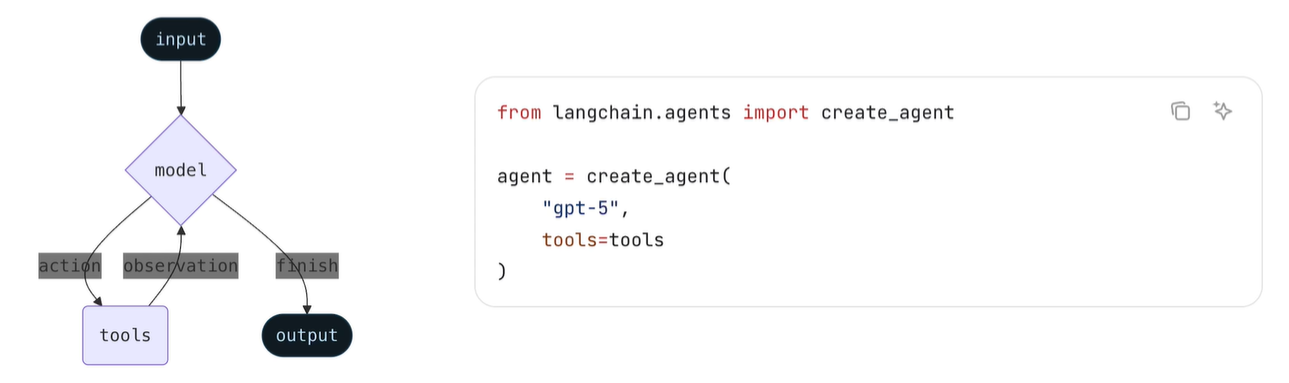
工具 LLM智能体循环运行各种工具以实现目标。智能体持续运行,直到满足停止条件为止(即模型发出最终输出或达到迭代次数限制)。
create_agent 提供可用于生产环境的代理实现,使用LangGraph构建基于图的代理运行时。
定义工具 基本工具定义 1 2 3 4 5 6 7 8 9 @tool def search_database (query: str , limit: int = 10 ) -> str : """ 在客户数据库中查询数据 Args: query: 要查询的搜索词 limit: 返回的最大结果数 """ return f"这个查询找到了{limit} 条结果"
自定义工具名称 1 2 3 4 5 6 7 @tool("web_search" def search (query: str ) -> str : """ 在网上搜索信息 """ return f"{query} 的查询结果" print (search.name)
自定义工具描述 1 2 3 4 5 6 @tool("calculator" , description="执行算术计算,用它解决各种数学问题" def calc (expression: str ) -> str : """ 计算数学表达式 """ return str (eval (expression))
注意:以上工具仅作演示,并没有实现任何功能,如需实现功能需要自行补充。
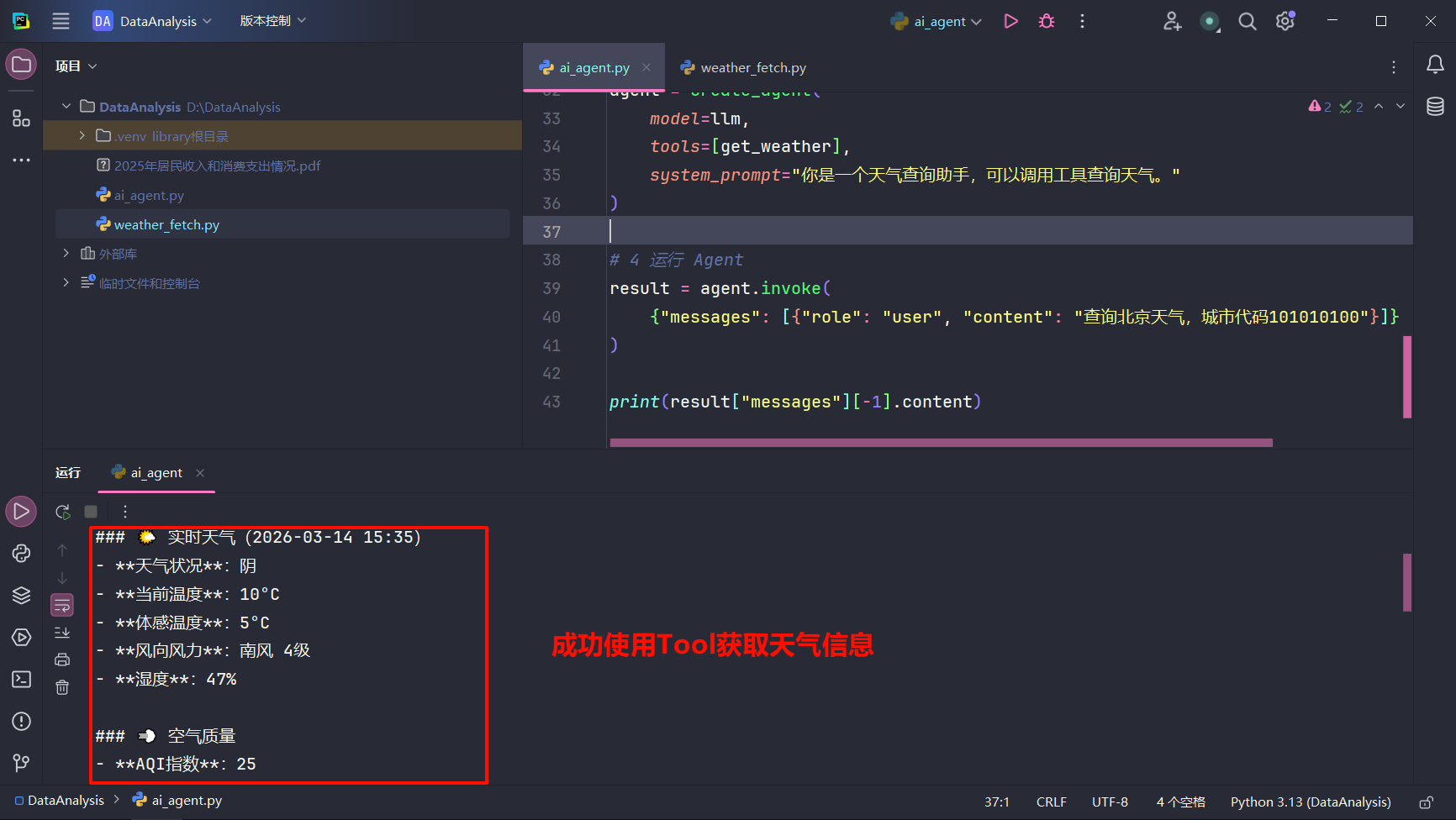
完整实例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import osimport requestsfrom langchain_openai import ChatOpenAIfrom langchain_core.tools import toolfrom langchain.agents import create_agentllm = ChatOpenAI( api_key=os.getenv("HUAPIKEY" ), model="zai-org/GLM-5:novita" , base_url="https://router.huggingface.co/v1" ) @tool def get_weather (id : str dict : """ 获取城市天气 Args: id: 城市代码,例如:101010100 Returns: 查询城市天气 """ url = f"http://aider.meizu.com/app/weather/listWeather?cityIds={id } " response = requests.get(url) return response.json() agent = create_agent( model=llm, tools=[get_weather], system_prompt="你是一个天气查询助手,可以调用工具查询天气。" ) result = agent.invoke( {"messages" : [{"role" : "user" , "content" : "查询北京天气,城市代码101010100" }]} ) print (result["messages" ][-1 ].content)
工具定义函数中一定要写函数注释,否则LLM不知道这个工具的作用,也就不会自动调用这个工具。
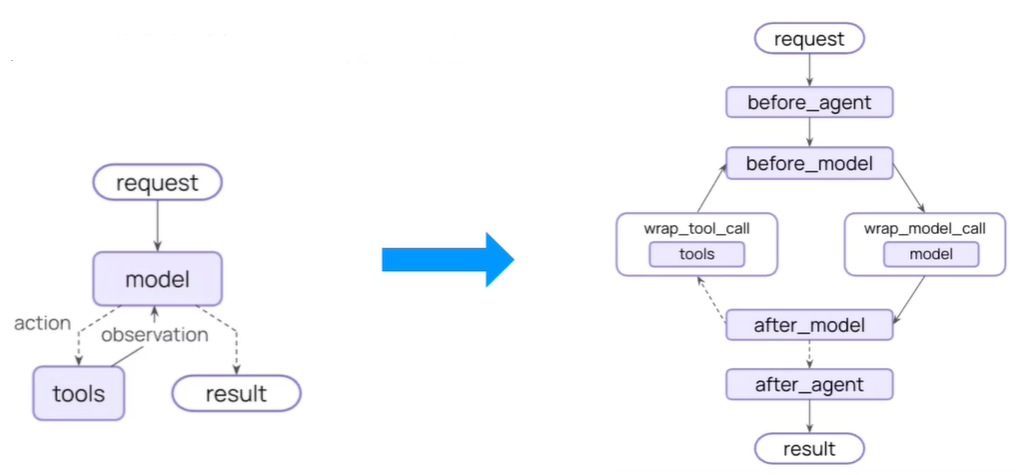
中间件 中间件是一种流程控制机制,用于在智能体执行过程中拦截、修改或增强请求与响应的处理逻辑,而无需修改核心 Agent 或工具的代码。
中间件在每个步骤之前和之后都会暴露钩子(函数)。
内置中间件 Summarization SummarizationMiddleware 是总结摘要的中间件,当接近会话次数上限时,自动汇总对话历史记录。
非常适合:
持续时间过长的对话超出了上下文窗口。
多轮对话,历史悠久。
在需要保留完整对话上下文的应用中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import osfrom langchain.agents import create_agentfrom langchain.agents.middleware import SummarizationMiddlewarefrom langchain_openai import ChatOpenAIllm = ChatOpenAI( api_key=os.getenv("LCAPI" ), model="LongCat-Flash-Lite" , base_url="https://api.longcat.chat/openai" ) agent = create_agent( model=llm, tools=[], middleware=[ SummarizationMiddleware( model=llm, trigger=('tokens' , 4000 ), keep=('messages' , 20 ), summary_prompt="可以自定义进行摘要的提示词" ) ] ) response = agent.invoke({ "messages" : [ {"role" : "user" , "content" : "你好" } ] }) print (response["messages" ][-1 ].content)
HumanInTheLoop 人机交互中间件Human In The Loop(HITL)允许您在代理工具调用中添加人工监督。
当模型提出可能需要审核的操作(例如,写入文件或执行SQL)时,中间件可以暂停执行并等待决策。
它通过检查每个工具调用是否符合可配置的策略来实现这一点。如果需要干预,中间件会发出中断以暂停执行。图状态使用LangGraph的持久层保存,因此执行可以安全地暂停并在稍后恢复。
决策类型
描述
实例
approve
该行动按原样批准并执行,未做任何更改。
请按原样发送电子邮件草稿
edit
工具调用经过修改后执行。
发送电子邮件前请更改收件人
reject
工具调用被拒绝,并在对话中添加了解释。
驳回邮件草稿并解释如何修改
未完待续……